An Initiative of the United Nations Environment Programme (UNEP)
| SECTION: | INTRODUCTION | ||||
| TITLE: | Informational Symbiosis of Microbial Taxonomy and Ecology | ||||
| BY: | Micah I Krichevsky | ||||
| LABEL: | MTE | UPDATED: | 31 Dec 1997 | ||
Relationship Between Biotechnology And Classification
Interdisciplinary Communication
Comparison Between A "Probe" Method And Culture
Building A Dictionary For Microbiology
In biotechnological processes which utilize single strains of microorganisms, specifying the characteristics of the desired clone is the first requirement. Once decided, the clone must be obtained by one of three means: isolation from nature, get a copy frion from nature, get a copy from a collection, or fabricate the clone by some method of induced mutation. The usual next step is to give the clone a name if it fits into a known class.
_________
| |
| PROCESS |
| DESIGN |
|_________|
_______|_______
| |
| CLONE |
| SPECIFICATION |
|_______________|
____________|______________
_____|___ __|___ _____|_____
| | | | | |
| ISOLATE | | COPY | | FABRICATE |
|_________| |______| |___________|
|_____________|______________| ________________| _________________
| / \
|--------------<CLONE DESCRIPTION >
____|____ \_________________/
| |
| PROCESS |
|_________|
Many processes in biotechnology require knowledge of the biodiversity of a site. The site is sampled and the organisms classified. Two common examples are 1) the introduction of an organism into a site wherein the fate of the organism in relationship to the existing population must be followed and 2) studying an indigenous population of organisms prior to and during a bioremediation treatment. In the later case, we try to predict the potential efficacy of adjusting environmental conditions to facilitate the remediation (e.g., adding agricultural fertilizer to promote utilization of hydrocarbons).
We put labels on groups of similar concepts for convenience of thinking about them. We labels words as nouns, verbs, and so forth. We belong to clans, tribes, religions, races, countries, and regions to which we give names. Classes of life forms are classified in two main frameworks. First, we classify them based on their history (phylogenetic groups) along with what they are capable of doing (phenetic groups). Second, we classify them with respect to their relationships to their environment and other life forms within that environment (ecologic groups).
The first framework is established without regard to habitat. That is, a classification based solely on genetic or phenetic characterization is possible on organisms without regard to their source. Such classification can be accomplished solely with organisms from culture collections. The classification requires no knowledge of source or f source or habitat.
To classify organisms in terms of ecology depends absolutely on knowledge of where the organisms normally live. Ecologic studies can be performed on organisms from culture collections, however the information on the source of the organisms must be available. The more detailed the source information given, the more precise the study. The source information will require interdisciplinary communication. For example, many modern ecologic studies use advanced geography methods (Geographical Information Systems or GIS) to describe the place of sampling.
As detailed later, the classes in either framework, taken together, describe aspects of diversity. Clearly, culture collections are repositories for diversity information as well as the organisms themselves. Further, culture collections are repositories containing much of the working material for biotechnology.
Consider the persons and disciplines involved in devellved in developing such processes: the molecular biologist models the insertion of the new gene, the biologist finds an organism containing the gene, the chemist predicts the structure and function of the product, the immunologist finds epitopes for antibody adsorption to purify the product, the microbiologist projects the new growth rate, morphology, and biochemistry of the host strain, the regulator predicts hazard, and the ecologist predicts long term interactions. Each of these disciplines have their own vocabulary and conventions of communication. Modern biotechnology clearly requires interdisciplinary communication.
Even within a discipline such as microbiology, communication problems exist. The most common way of describing an organism is through the species name. Thus, we "identify" an organism as belonging to a particular species. However, different methods such as pure culture phenotypic assessment methods can give very different identifications from immunologic or genetic probes. This problThis problem becomes critical if we wish to follow changes in the microbial populations of two sites by different methods.
Consider the following example where the same samples from human periodontal pockets were sampled. The first column of the table presents the percentage of samples wherein each organism was identified and scored as present by both the immunologic probes and by traditional pure culture techniques. The next two columns give the percentage of samples wherein the methods disagreed. The last column gives the percentage of times the two methods detected the organism divided by the positive agreements plus the disagreements (col. 1/col. 1 + col. 2 + col. 3).
| PERCENT OF POSITIVE SITES SAMPLED | ||||||||
| ORGANISM IDENTIFIED | PROBE+
CULT + |
PROBE+
CULT - |
PROBE-
CULT + |
LEVEL OF
AGREEMENT | ||||
| A.actinomycetemcomitans | 0 | 11 | 0 | 0 | ||||
| Actinomyces viscosus | 72 | 6 | 11 | 81 | ||||
| Bacteriodes forsythus | 22 | 33 | 0 0 | 40 | ||||
| Bacteroides gingivalis | 33 | 11 | 0 | 75 | ||||
| Bacteroides intermedius | 44 | 6 | 11 | 72 | ||||
| Capnocytophaga species | 11 | 17 | 44 | 15 | ||||
| Eikenella corrodens | 6 | 6 | 11 | 26 | ||||
| Eubacterium saburreum | 11 | 11 | 6 | 39 | ||||
| Fusobacterium nucleatum | 50 | 17 | 11 | 64 | ||||
| Streptococcus mutans | 6 | 22 | 6 | 18 | ||||
| Streptococcus sanguis | 39 | 17 | 28 | 46 | ||||
| COLSPAN="4"> Wolinella recta | 17 | 44 | 0 | 28 | ||||
The agreement ranges from none to a high of 81%. Conclusions based on incidence of these organisms in the sampled sites will vary depending on the method of detection used. This is a clear example of problems of communication that exist even in closely related branches of microbiology, immunologic assay and pure culture microbiology.
The limiting factor in interdisciplinary communication is the ability of the persons involved to understand the vocabulary and nomenclature of all the disciplines included to the level needed to reason with the information. The user of information must receive input from disparate disciplines each of which have their own jargon. The practitioners of the various disciplines invent new words and give new meaning to oldeaning to old words as their disciplines advance. This inevitable practice facilitates communication locally but creates noise globally.
We would like to build a dictionary for each discipline, i.e., a standard nomenclature and vocabulary. Our immediate field is straightforward. We are comfortable with the words we use. However, we have problems using the standards of other disciplines.
Illustrative of these points is the task of building a standard nomenclature and a vocabulary to describe species of microorganisms. The building of such a dictionary has two distinct aspects: the names of organisms and the attributes of organisms. They must follow different sets of rules. We shall consider the "dictionary" for attributes of organisms in a separate discussion.
Perhaps the most pervasive element in biological databases is, and will continue to be, the "name" given to the" given to the taxonomic place of the organism. Usually this will revolve around the species name. Within each of the major groups of biological entities good standardization of rules of nomenclature exits. The rules for each group are maintained by the several nomenclatural bodies set up within two of the Unions adhering to International Council of Scientific Unions: the International Union of Biological Societies and the International Union of Microbiological Societies.
The rules for naming the various major groups of microorganisms fall under different Codes of Nomenclature. The code for viruses is managed by the International Committee for the Taxonomy of Viruses. The fungi and algae are covered by the Botanical Code. With some redundancy, the Zoological Code covers algae and protozoa. Such organisms as the cellular slime molds, which are amoebae that differentiate into fungal appearing forms also are covered in both codes.
The bacteria have their own International Code of Bacterial Nomenerial Nomenclature. The rules of this code are promulgated by the international Committee on Systematic Bacteriology. A major distinction between the Bacteriological Code and the others is that all names of bacteria were reset by the publication of the Approved List of Valid Names in 1980. Additions and emendations must be published in the International Journal Of Systematic Bacteriology (IJSB). All new taxa must be listed in the IJSB for validity, regardless of where the original description appeared. Thus, only one journal need be consulted for valid names of bacteria and only from 1980 onward.
The following outlines the existing codes accepted in microbiology:
=> CODES OF NOMENCLATURE
VIRUSES => ICTV (IUMS)
FUNGI, ALGAE => BOTANICAL CODE (IUBS)
PROTOZOA, ALGAE => ZOOLOGICAL CODE (IUBS)
BACTERIA => BACTERIOLOGICAL CODE (IUMS)
The rules allow scientific s allow scientific conflict. Unfortunately for the database producer, a clear set of authoritative names is not
available from the nomenclaturists in most cases. With the exception of the International Committee on Taxonomy of Viruses, the committees responsible for establishing the naming rules do not judge scientific validity of the names, only the correct etymology in some cases.
A continuing problem faced by database and culture collection catalogue producers is the lack of availability of such "official" lists in publicly-accessible, machine readable form. The publishers of these lists (and many other lists of standards) often maintain these lists in computer files. However, the prevailing view of these publishers is that they wish to sell hard copy (books or journals) rather than have people make and use electronic copies. In some cases, these lists have been retyped into databases and made available to the public as value-added databases.
There are many reasons for establishing a culture collection. Most have an ecological motivation of some sort. The major exception is simply obtaining cultures from another collection. In this context, we can consider medical collections as ecologically based since the ecology involved is that of the host organism. To start a biotechnology collection the econiche where the organism with the desired properties is sampled and candidate organisms accessioned into the collection. The following scheme illustrates the iterative nature of establishing a culture collection from nature and classifying the organisms thus obtained.
ESTABLISHING STRAIN POPULATION FOR ACCESSION AND STUDY
DATA GATHERING ON ISOLATES IN EACH CATEGORY
DATA MANAGEMENT AND QUALITY CONTROL
ANALYSIS
CLASSIFY ISOLATES
As the collection grows, the above process is repeated and the taxonomy is updated. Why not use a "standard" taxonomy?
As stated above, there is no "official" scientific definition of each taxon. Therefore, the individual microbiologist must use
their best professional judgement to identify a new isolate. As we shall see, computers can help in this process. The picture is murky when we consider the application of "standard test methods" to study of microbial populations and
their member taxa. In almost all cases, the consideration of microbes in the environment falls victim to oversimplification.
The foremost, but hardly only, oversimplification is to consider the microbes on the species level when it is a fundamental
tenet of microbiology that phenotypic expressionotypic expression of a particular functional capacity is an isolate or strain-specific
property. (While there is a conceptual difference between the "isolate" and "strain", discussed later, the distinction is not
required for the immediate discussion.) The practical importance of this over-generalization is that we extrapolate from one population to another, assuming the
spectrum of organisms is applicable across these classes. Yet, microbial ecologists know very well that seemingly small
changes in the harboring econiches yield organisms that are often different enough to be "unidentifiable" to species level.
"Often" translates to 50-100% of the isolates. The information required to study ecology in terms of both taxonomy and diversity may be outlined as follows. Each of the
following categories of information become data elements in a database. RECORDS REGARDING INDIVIDUAL ISOLATES The resulting data are entered into a computer. Many database management systems exist. Their internal logic of data
storage varies considerably. However, the resulting database may be visualized as a simple two dimensional table no
matter which system is used. For ecologic purposes, we wish to ascertain properties of the sampleties of the sample population as a whole. The data to do so may fall into
the following categories. RECORDS REGARDING POPULATIONS SAMPLED In these information gathering procedures, we should accept the reality of the following statements. WE CANNOT: WE CAN: classify & identify isolates The microbial methodologies for characterizing microorganisms fall into two broad informational classes: open or closed.
The kinds of questions which may be answered with these classes are quite different. The differences are important and
often ignored. An open method system is capable of characterizing any organism submitted. A set of attributes is assessed for all
organisms. Direct microscopy and non-selective isolation and cultivation are the most common procedures used. Using
open method logic, many workers have demonstrated the feasibility of characterizing isolates by their enzyme composition.
A whole industry of identification kits with standardized tests arose using panels of biochemical tests. Growth of the
organisms may or may not be required in the test procedures. A closed method is one in which presence or numbers of only one microorganism or a discrete list of organisms can be
assessed. The assessment is performed by determied by determining ability to grow in a selective medium or by some form of reactivity
against a reference panel of reagents. The methods do not actually assess identity. They have some (often unknown) range
of reactivity. The actual range usually varies with the particular selective medium or reagent as well as the econiche being
sampled. Antibody screening and nucleic acid probing are among the oldest and newest of these methodologies. Some informational characteristics of open and closed methods are illustrated in the following table.
BIOLOGICAL ACTIVITY The above discussion focuses on the individual clones isolated from a sample of a population. For many reasons, we wish
to know something of the activity of the population as a whole, i.e., the capacities of the community. There are various
ways of reporting such information. REPORTED BY POPULATION OR SAMPLE. Diversity measures compute various statistics from the number of taxa
and the numbers of members of each taxon in a sample. As the dynamics of the sample site vary with time and changing
conditions, so too the diversity will change. DIRECT ASSAY. The simplest method to determine activity in a sample is direct assay. For example, the capacity of
aliquots of a dilution of the sample to utilize various substrates is subject to direct teect to direct test. The test conditions usually are
similar to those used for pure culture tests. INDIRECT SYNTHESIS FROM CHARACTERISTICS OF THE INDIVIDUAL CLONES. The combined ability of the
mixed population of a sample will have a greater capacity to react with a greater spectrum than the members of the
population in isolation. That is, many more tests likely will be positive than for any single isolate. Another difference
between the consideration of isolate versus population characterization is the lack of precedent for choosing
characteristics to assess. Microbiologists have built a foundation of knowledge for characterizing isolates in the course of
taxonomic studies on microbiota. The characteristics delineated in such studies could be a rational starting point for
establishing a convenient panel of tests which can classify samples into groups associated with specific soil conditions. Two different strategies will help circumscribe the search the search for one or more useful panels of characteristics deemed useful in
classifying soil samples. We can search datasets obtained by characterizing pure culture isolates for applicable features
and we can assess commercial panels (kits) from clinical microbiology for their utility for describing whole populations. The first procedure would be to reconstruct the presumptive resultant physiological capacities of each sample by
collapsing the physiological data on all strains isolated from a sample into a single record. That is, if any strain from the
sample is positive for a given characteristic, the characteristic is scored as positive. This is illustrated in the following
table.
For the sample as a whole, the pattern is: +-++. No single strain exhibits the resultant pattern. Since characters 2 and 3
exhibit feature freibit feature frequencies of 0 and 100% respectively, these would be good possibilities as classifying features, with the
obvious caveat that the same pattern does not occur in other classes of samples. The method for analysis of this data to
disclose useful features will be cluster analysis of the binary data accumulated on the sample level as above. The data will
be edited, prior to analysis, to amplify the signal to noise ratio. The clusters will be compared to the conditions recorded
for each sample. Assuming that the patterns of features do contain the necessary richness of meaningful information, a
"taxonomy" of conditions will be constructed. This technique of analysis and classification makes no assumptions about the underlying causal relationships or which
measures are "important". If a strong association exists, it should be discernable. Describing diversity of either organisms or econiches we must establish the spectrum of species found in the samples.
Thus, we needus, we need some operational definitions. Consider the words: Species, Strain, Isolate. Here we do not considering the
metaphysical definition of "species". Leave that to the biological philosophers. We want to manipulate data in a frame of
reference that is consistent, even if arbitrary. Simplest first. We can define the description of an isolate as a single assemblage of data (a record) resulting from the
observations of a clone. (The observations may be of phenotype, serotype, genotype, virulence, host range, etc. All these
methods have been used to define or describe isolates, strains, and species.) There may be redundant observations of the
properties of the clone for error reduction. Each observation has only one "true" value (either numerical or
presence/absence). Recording incidence is a trivial concept. An isolate can only occur once. However, recording the
source of isolation is usually quite important. Rampant confusion abounds in use of the term "strain". Often "n". Often "strain" and "isolate" are used interchangeably. Nothing
wrong if clearly stated that the isolate definition is the one that obtains. However, a strain commonly is defined as a series
of isolates that are "identical" (as in the annual search for the new flu strain). Thus, at least two isolate records must be
compared to establish identity. Since identity is required, any single isolate definition may be the definitive record.
Describing incidence of the strain becomes a two step process. First, identity must be confirmed by exact match to the
definition (allowing for some observational error). The result of this step can only be true or false (identity|no identity).
Second, the time and place of isolation of the individual isolations must be recorded. Only the incidence data is further
analyzable. A species is described in terms of at least one record describing one or more isolates which are distinctly different from
other isolates. The requirement of distinction implies some decissome decision rule (either codified or personally operational) as to
what is sufficient distinction. Between identity (strain) and distinction (species) lies the area of similarity. We speak of
"atypical" strains, variants (serovars, pathovars, etc.). This verbal imprecision actually reflects the degree of similarity,
ascertained by some distance measure, to the idealized strain description. Thus, the definition of a species has two
components: the idealized strain description and the decision boundary of allowable variation. Incidence of species in space and time is a statistical problem in that the incidence must be derived from the individual
isolate records. First, the species "identity" (actually similarity) must be computed or deduced from experience. Second,
the distributions must be calculated or mapped. At this point, the raw data from which the species is determined often is
discarded. One sees "atypical E. coli" on patient records with no information as to what made them "atypical"atypical". Useful
epidemiological studies are thus precluded. An even more basic problem occurs when these distinctions are blurred. The logical difference between the concept of
isolate and species impacts directly on the design of data structures. We find data elements for both in the same data
structure. What is the "habitat" of an isolate? What is the "source of isolation" of a species? What is the virulence of a
"species"? The host range of an isolate can be determined experimentally. That of a species must be inferred from the data
accumulated by test of the host ranges of a representative set of isolates or by inference based on source of isolation of
many isolates. Consequently, isolate and strain data can be recorded largely as presence|absence or continuous variables. Species data
usually takes the form of numerical data (frequencies, continuous variables, ratios, ranges, distributions, etc.) Strain data
can be calculated from isolate data. Species data is calculateis calculated from isolate or strain data. Species data cannot yield strain
data and strain data cannot yield isolate data. These concepts are summarized below. ISOLATE => OBSERVATIONS OF A CLONE => A SINGLE ASSEMBLAGE OF DATA (A RECORD) -> PHENOTYPE -> SEROTYPE -> GENOTYPE -> VIRULENCE -> HOST RANGE => ONE "TRUE" VALUE/OBSERVATION => INCIDENCE = ISOLATE CAN ONLY OCCUR ONCE => SOURCE OF ISOLATION USUALLY QUITE IMPORTANT STRAIN => SERIES OF ISOLATES THAT ARE "IDENTICAL" => ISOLATE RECORDS COMPARED TO ESTABLISH IDENTITY => ANY SINGLE ISOLATE THE DEFINITIVE RECORD => INCIDENCE OF STRAIN - TWO STEP PROCESS 1> IDENTITY = EXACT MATC
1> IDENTITY = EXACT MATCH TO THE DEFINITION 2> TIME AND PLACE OF ISOLATION => ONLY THE INCIDENCE DATA IS FURTHER ANALYZABLE SPECIES => 1 RECORD COMPUTED FROM MULTIPLE ISOLATES => ISOLATES DIFFERENT, BUT NOT TOO DIFFERENT => OPERATIONAL SPECIES DEFINITION - 2 COMPONENTS 1> IDEALIZED STRAIN DESCRIPTION > HYPOTHETICAL MEDIAN ORGANISM 2> DECISION BOUNDARY OF ALLOWABLE VARIATION > CODIFIED (COMPUTED STATISTIC) > PERSONALLY OPERATIONAL - EXPERIENCE - KEY DIVERSITY. A basic measure of change in an ecosystem is the measurement of diversity. Two aspects of diversity must be
measured: 1) "Genetic" or "systematic" diversity, i.e., the extent and nature of variation within and between classes ofwithin and between classes of
organisms and 2)"ecologic" diversity, i.e., the extent and nature of variation within and between sampled sites. Ecologic
diversity ultimately is a geographically based function of the genetic diversity. The way we study these two aspects differs in a number of ways. Sampling strategies for genetic diversity are selective,
driven by phenetics whereas ecologic diversity requires random, "non- selective" sampling. The unit for data reporting
usually is the isolate for genetic and the species for ecologic diversity. The data analysis strategy is based on inter- and
intra-group similarity of isolates for genetic diversity. Common measures of ecologic diversity include information content
and measures of variance. Finally, the outputs from these analyses are some form of taxonomic description for genetic
diversity and geographic distributions and correlates in the case of ecologic diversity. Unfortunately, there is no single, comprehensive suite of cosuite of computer programs which supports data acquisition,
management, and the varied analyses that are required for a full consideration of both genetic and ecologic diversity. To
summarize: GENETIC OR SYSTEMATIC DIVERSITY: extent and nature of variation within and between classes of organisms ECOLOGIC DIVERSITY: extent and nature of variations within and between sampled sites ECOLOGIC DIVERSITY ULTIMATELY IS A GEOGRAPHICALLY BASED FUNCTION OF THE GENETIC
DIVERSITY. The properties of each of these types of diversity are summarized in the following table.
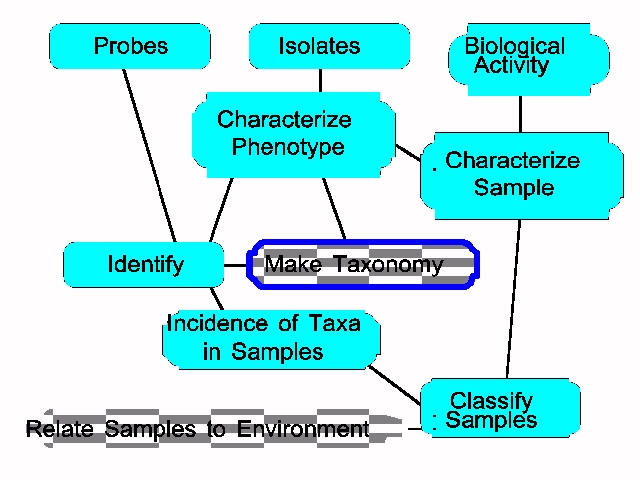
A Numerical Taxonomy Process in classifying both types of diversity is: Create table: Isolates X characters Determine similarity of isolate pairs Procedure 1 Sort in order of similarity Phenotypic|phylogenetic classification Procedure 2 Sort in order of isolation site Site classification Procedure 3 Invert Isolates X characters matrix Determine similarity of character pairs Sort in order of similarity Yields classification of characters The following figure summarizes the concepts involved in studying an ecologic site by consideration of both isolates and
samp of both isolates and
samples.
|Isolate|Sample|Taxon|History| Features|
| 1 | | | | - - + + |
| 2 | | | | + - + + |
| 3 | | | | - - + - |
| . | | | | + - - - |
| N | | | | + - + - |
CHARACTERIZATION METHOD
OPEN
CLOSED Clones
"Any and All"
Selected Attributes assayed/taxon
Many
One Kind of attributes
Physiologic, Anatomic
Macromolecular Examples
"Non-selective" pure
culture tests,
Microscopy
Serology, Phage typing,
Nucleic acid probes Sensitivity
Low
High Common use
Diversity, Populations
Incidence of specific
taxa
CHARACTER
1
2
3
4 ISOLATE 1
+
-
+
- ISOLATE 2
-
-
+
+ ISOLATE 3
+
-
+
- ISOLATE 4
-
-
+
- SAMPLE
+
-
+
+
GENETIC/SYSTEMATIC
ECOLOGIC SAMPLING
SELECTIVE, DRIVEN BY PHENETICS
"NON-SELECTIVE", RANDOM UNIT FOR
ANALYSIS
ISOLATE OR MACROMOLECULAR
SEQUENCE
SPECIES ANALYSIS
STRATEGY
INTER- AND INTRA-GROUP SIMILARITY
INFORMATION CONTENT, MEASURES OF
VARIANCE OUTPUT
TAXONOMY
GEOGRAPHIC DISTRIBUTIONS AND
CORRELATES